Die Problematik Duplicate Content gehört zu den Basics in der Suchmaschinenoptimierung. Jeder SEO und Webseitenbetreiber hat sich wohl oder übel schon einmal damit beschäftigen müssen. Es gibt sehr viele Möglichkeiten und Umstände, die zu Duplicate Content führen können. Häufig wissen Webseitenbetreiber noch nicht einmal, dass sie ein Duplicate Content Problem haben. Erst durch Rankingverluste oder das Fehlen von Rankings überhaupt, werden Probleme durch Duplicate Content identifiziert.
Unter Duplicate Content versteht man im Allgemeinen das Bereitstellen von identischen Inhalten auf verschiedenen URLs derselben oder unterschiedlichen Domains. Dies betrifft überwiegend den Textbereich von Webseiten, obwohl Fotos, Videos und dergleichen auch darunterfallen. Man differenziert zwischen internem und externem Duplicate Content. Bei internem Duplicate Content werden die gleichen Inhalte ein und derselben Domain auf verschiedenen URLs angeboten. Von externem Duplicate Content spricht man, wenn die gleichen Inhalte auf verschiedenen Domains verwendet werden.
Suchmaschinen mögen duplizierte Inhalte generell nicht. Bei internem Duplicate Content kann es zu Rankingeinbußen kommen, da Suchmaschinen nicht immer verstehen, welche URL für bestimmte Keywords ranken soll. Bei externem Duplicate Content stehen Suchmaschinen vor der Problematik zu erkennen, welche Domain den Originalcontent zur Verfügung stellt und welche diesen „nur“ duplizieren.
Im Folgenden werden die 5 häufigsten Fehler vorgestellt, welche wir häufig durch Analysen der Domains unserer Kunden und deren Wettbewerber feststellen.
Bei der Verwendung von original Produktbeschreibungen und Texten von Herstellern kommt es immer wieder zwischen verschiedenen Domains zu Duplicate Content. Besonders Online Shops sind von diesem Problem betroffen. Nicht selten verwenden beispielsweise Elektronik-Online Shops direkt den Content, der von den Herstellern geliefert wird. Dieser ist häufig sehr umfangreich und enthält alle wichtigen Informationen zum Produkt und Hersteller. Dem User ist es in diesem Fall sicherlich egal, ob es duplizierter oder einzigartiger Content ist. Suchmaschinen stellt dies allerdings vor ein Problem, wenn diese Originaltexte von verschiedenen Onlineshops mit den gleichen Produkten verwendet werden. Welche Domain stellt nun den Original Text zur Verfügung? Hier gewinnt häufig die Domain mit dem größten Trust die besten Positionen in den Suchmaschinen.
Die Lösung des Problems ist einfach, allerdings auch sehr Zeit- und Ressourcen-raubend. Die Empfehlung lautet hier, das Verfassen von einzigartige Texten, kann einen Rankingvorteil verschaffen. Das Schreiben von einzigartigen Texten macht sich vor allem bei Produkten bezahlt, die sehr häufig von Usern direkt gesucht werden. So macht es sicherlich Sinn für das neuste Smartphone von Apple oder Samsung einen umfangreichen einzigartigen Produkttext zu verfassen und damit klar im Vorteil gegenüber der Konkurrenz zu sein, welche noch Originaltexte der Hersteller verwendet.
Auch für Online Shops, die nicht sehr viele Produktsuchen haben, lohnt es sich die Qualität der gesamten Domain mit einzigartigen Produkt- und Herstellertexten zu verbessern und so für die gesamte Webseite einen Rankingvorteil zu schaffen.
Es gibt auch verschiedene technische Ursachen für Duplicate Content. Eine davon ist ein mangelhaftes URL-Management. Ziel des URL-Managements ist es, alle verschiedene URL-Variationen auf eine Form zusammenzuführen. Hierzu gehören die Unterscheidung von Groß- und Kleinschreibung, die Verwendung von Trailing-Slashes, oder die Eingabe von www. vor dem Domainnamen.
Grundsätzlich sollte eine URL-Version (z.B. alles kleingeschrieben, mit www. und ohne Trailing-Slash) als kanonisch definiert werden, alle anderen Versionen werden dann per 301 Redirect auf die kanonische Version weitergeleitet. Andernfalls besteht die Gefahr, dass identische Inhalte unter verschiedenen URLs erreichbar sind: Ein klarer Fall von Duplicate Content.
Zur Prüfung des URL-Managements existieren verschiedene Tools, sehr übersichtlich und kostenfrei ist zum Beispiel httpstatus.io:
Quelle: https://httpstatus.io/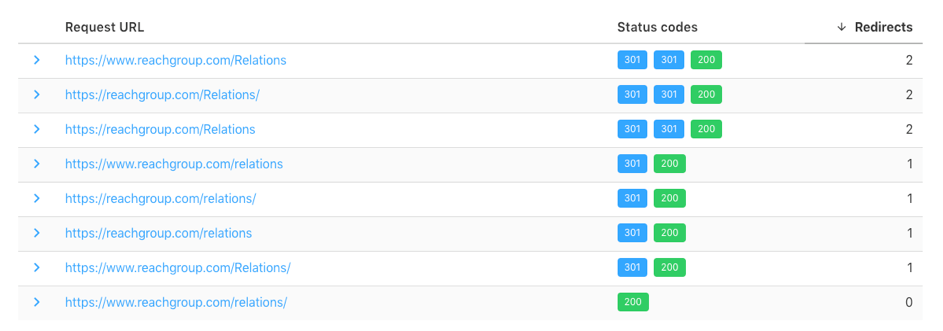
Sollte hier auffallen, dass unterschiedliche URL-Varianten einen 200 Status Code ausgeben, müssen per htaccess-Datei automatische Weiterleitungsregeln definiert werden.
Eine häufige Quelle für (Near) Duplicate Content stellen Filter- und Sortierungsfunktionen dar. Oft werden hierfür URL-Parameter verwendet, etwa um in einer Produktkategorie die Einträge nach Preis oder alphabetisch zu ordnen. Der Inhalt der Seite ändert sich dadurch für Suchmaschinen nur marginal, es entsteht aber eine neue URL. In Verbindung mit verschiedenen Filteroptionen entstehen so schnell Tausende verschiedene URLs, die alle nahezu denselben Inhalt haben.
Davon abgesehen, dass hierdurch massive Probleme mit der Crawlingeffizienz verursacht werden können, drohen auch Duplicate Content Probleme, wechselnde rankende URLs und Keywordkannibalisierung. Eine Lösung kann zum Beispiel die Verwendung des Canonical-Tags oder der Einsatz von Noindex sein. Teilweise ist auch eine Maskierung der Filter- und Sortierungsfunktionen mittels PRG-Pattern sinnvoll. Hier allein auf die Parameterbehandlung in der Google Search Console zu setzen, greift meistens zu kurz.
Um Duplicate Content Probleme durch Filter oder Sortierungen zu erkennen, hilft entweder ein Blick in die Google Search Console (Bericht zur Indexabdeckung und individuelle URL-Prüfung) oder eine Analyse der Server Logfiles.
Werden die Inhalte einer Domain für verschiedene Länder auf unterschiedlichen URLs angeboten, können doppelte Inhalte entstehen. Bietet etwa ein Online Shop identische Inhalte für Nutzer aus Österreich und Deutschland an, die unter verschiedenen URLs aufrufbar sind, kann dies für Suchmaschinen Duplicate Content darstellen.
Grundsätzlich wurde für die Sprach- und Ländersteuerung das Hreflang-Tag eingeführt, mit dem alle verschiedenen Sprach- und Länderversionen ausgezeichnet werden. So wird Google angezeigt, welche Version in welchem Land ausgespielt werden soll.
Das Hreflang-Tag wurde aber nicht entwickelt, um Duplicate Content aufzuheben und Google empfiehlt, für jedes Land individuelle Inhalte anzubieten, auch wenn in zwei Ländern dieselbe Sprache gesprochen wird. In der Praxis zeigt sich jedoch, dass das Hreflang-Tag bei korrekter Implementierung eine Trennung verschiedener Länderversionen auch bei doppelten Inhalten bewirkt. Probleme treten aber häufig auf, wenn das Hreflang-Tag fehlerhaft eingesetzt wird, zum Beispiel bei fehlenden Rücklinks oder falschen Sprach- und Ländercodes.
Um die Sprach- und Ländersteuerung zu überprüfen hilft es, Sichtbarkeit und Rankings einer Domain in verschiedenen Ländern mittels Sistrix, Searchmetrics oder der Google Search Console zu überwachen. Hier wird dann schnell deutlich, wenn etwa für Deutschland bestimmte URLs in Österreich ranken oder umgekehrt.
Im Gegensatz zu klassischem Duplicate Content, handelt es sich bei „Near“ Duplicate Content um einzelne Ausschnitte, die aus dem Originalcontent vielfach verwendet oder nur leicht abgeändert werden. Im Prinzip stellen statische Footer und Sidebars, die mehr als nur Links enthalten, eine Form von Duplicate Content dar. Aber auch Teasertexte, die häufig auf Übersichtsseiten von Blogs oder Magazinen verwendet werden, können als Near Duplicate Content betrachtet werden. Sehr häufig werden für diese Teaser die ersten Zeilen des Artikels verwendet, statt dafür einen individuellen Text zu veröffentlichen.
Kann sich Near Duplicate Content aber schlecht auf das Ranking auswirken? Problematisch wird es, wenn statt der exakten URLs nun Übersichtseiten ranken oder Suchmaschinen nicht entscheiden können, welche Seite nun relevanter ist.
Falls statische Footer oder Sidebars Probleme verursachen, sollte hier über dynamische Elemente nachgedacht werden. So kann zum einen nicht nur das Near Duplicate Content Problem gelöst, sondern auch die interne Verlinkung optimiert werden.
Die Problematik Duplicate Content war, ist und wird auch in Zukunft ein Thema sein, mit dem sich SEOs und Webseitenbetreiber immer wieder beschäftigen müssen.
Fest steht, dass die Performance einer Webseite sehr stark von der Qualität und der technischen Implementierung des Contents abhängt. Duplicate Content kann einfach durch Unachtsamkeit oder aufgrund von Resourcenmangel, aber auch durch technische Fehler entstehen. Wichtig ist es, diese Fehler und Probleme zu erkennen und gegen diese vorzugehen. Nur so können sich Ranking und die Gesamtsichtbarkeit einer Webseite optimal entwickeln.
